第4章 XML配置文件¶
第 4 章¶
XML 配置文件¶
从本章开始,我们将暂时告别前端知识,进入 Web 后端技术的学习。接下来,我们会陆续学习 XML 配置文件、Tomcat 服务器、HTTP、Servlet 核心技术等 Web 后端的基础知识。本章主要介绍 XML 配置文件,重点掌握 XML 文件的作用,了解如何解析 XML 文件,为以后学习和使用 Java 框架做铺垫。
4.1 XML 简介¶
XML 技术由 W3C 组织发布,目前推荐遵守的是 W3C 组织于 2000 年发布的 XML1.0 规范。它是独立于软件和硬件的信息传输工具,并且作为一种纯文本,应用十分广泛,有能力处理纯文本的软件都可以处理 XML。
4.1.1 什么是 XML¶
XML 的全称为 Extensible Markup Language,叫作可扩展标记语言。它和前面学习的 HTML 很相似,都属于标记语言,不过两者的用途不同,HTML 主要用来显示页面数据,而 XML 则用来传输和存储数据。“可扩展” 的字面意思指 XML 允许自定义格式,但是这不代表开发人员可以随便编写 XML 文件。如图 4-1 所示,在 XML 基本语法规范的基础上,第三方应用程序、框架会通过设计 XML 约束的方式强制规定配置文件的内容,规定之外的都是不允许的,因此编写 XML 文件不仅需要遵循 XML 基本语法,还要符合第三方应用程序或框架给定的 XML 约束。
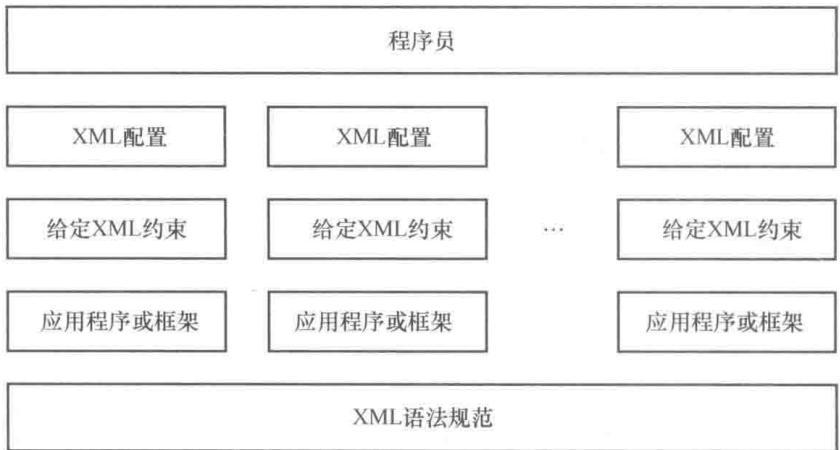
XML 语言独立于计算机、操作系统和编程语言,凭借其简单、可扩展、交互性和灵活性在计算机行业得到了广泛应用和支持,例如最基本的网站、应用程序的配置信息,一般都采用 XML 文件来描述。
4.1.2 XML 文件的应用¶
XML 作为独立于软件和硬件的信息传输工具,它可以存储数据、作为数据交换的载体,但最常见的
还是作为配置文件使用,例如 JavaEE 框架、SSM 框架大部分都是使用 XML 作为配置文件。
配置文件是给应用程序提供配置参数的文件,并且还可以初始化设置一些有特殊格式的文件。
常见的配置文件类型有 properties 文件、XML 文件、YAML 文件和 JSON 文件。
相信学过 Java 基础的读者,已经对 properties 文件有所了解,下面主要对比一下 properties 文件和 XML 文件,YAML 文件和 JSON 文件这里暂不涉及。
properties 文件的示例代码如下。
atguigu.jdbc.url=jdbc:mysql://192.168.198.100:3306/dbname
atguigu.jdbc.driver=com.mysql.cj.jdbc.Driver
atguigu.jdbc.username=root
atguigu.jdbc.password=atguigu
properties 文件是最简单的一种配置文件,编写过程中需要注意以下要求。
XML 文件的示例代码如下。
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!-- 配置 SpringMVC 前端控制器 -->
<servlet>
<servlet-name>dispatcherServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- 在初始化参数中指定 SpringMVC 配置文件的位置 -->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mvc.xml</param-value>
</init-param>
<!-- 设置当前 Servlet 创建对象的时机是在 Web 应用启动时 -->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dispatcherServlet</servlet-name>
<!-- url-pattern 配置斜杠表示匹配所有请求 -->
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
通过上述代码可以看出,XML 文件格式与 properties 文件格式大不相同。properties 配置文件容易理解,但只能赋值,适合简单的属性配置。而 XML 配置文件结构清晰,可以有多种操作方式,更加灵活,但编写过程比较复杂。
4.2 XML 基本语法¶
一个标准的 XML 文件一般由以下几部分组成,分别为文档声明、元素、属性、注释和特殊字符。
XML 文件形成了一种树结构,整体来看是由一个标记结点和一个根结点组成,它从 “根部” 开始,然后扩展到 “枝叶”。标记结点指的是文档声明,它只能出现在 XML 文件最开始的地方,根结点则有且仅有一个,然后文件中所有的数据都会以某种形式存储到根结点的子结点中。下面分别介绍 XML 文件的组成部分。
1. 文档声明¶
XML 文件的文档声明必须放在第一行,以 “<?xml” 开头,以 “?>” 结束,在 XML 文件的文档声明中,常见的两个属性为 version 和 encoding。其中 version 用来指定 XML 文件的版本,一般选择 1.0 版本,该属性是必须属性;encoding 用来指定 XML 文件的字符集,默认为 UTF-8,该属性是可选属性。示例代码如下。
其中,version 表示版本号,encoding 表示字符集。对于 XML 文件,如果声明必须遵循上述格式,当然,也可以不声明。
2. 元素¶
元素是 XML 中最重要的组成部分,也叫作标签。类似 HTML,所有元素均可拥有文本内容和属性,标签的用法也和 HTML 标签一样,分为开始标签和结束标签,标签中间写的是标签内容,标签内容可以是文本,也可以是其他子标签。如果标签没有任何内容,那么可以定义为单标签,如 <begin/>。标签可以嵌套,但是不能交叉嵌套,必须保证父标签与子标签的逻辑关系。值得注意的是,一个 XML 文件只能有一个根标签。另外,标签名必须符合标识符的命名规则,具体如下。
3. 属性¶
属性是元素的一部分,它必须出现在元素的开始标签中,不能出现在结束标签中。属性的定义格式如下所示。
其中属性值不能为空,且必须使用单引号或双引号括起来。一个元素可以有 0 个或多个属性,多个属性之间用空格隔开,但不能出现同名的属性。属性名也要符合标识符的命名规则。例如,前面 XML 文档声明示例中的 version 和 encoding 属性。
4. 注释¶
XML 文件的注释,以 “<!--” 开头,以 “-->” 结尾,注释不能写在 XML 文档声明前且不允许嵌套,并且支持多行注释。示例代码如下。
5. 特殊字符¶
XML 中共有 5 个特殊的字符,分别为 “&” “<” “>” “!” 和 “!”。如果配置文件中的值包括这些特殊字符,就需要进行特别处理。XML 对于上述字符提供两种转义方式,一种是通过预定义的实体引用表示,一种是采用 “<![CDATA [...]]>” 特殊标签,将包含特殊字符的字符串封装起来。
例如,标签由 “<” 和 “>” 组成,而对于大于号或小于号的使用,就可以借助实体引用。五个特殊字符对应的 XML 转义序列如表 4-1 所示。
表 4-1 五个特殊字符对应的 XML 转义序列
| 对应符号 | 实体引用 | |
| 小于 | < | < |
| 大于 | > | > |
| 单引号 | ' | ' |
| 双引号 | '' | '' |
| 和(and) | & | & |
例如,显示如下标签:<tcode></tcode>,标签内的文本内容为 “<tcode> 我喜欢写代码 </tcode>”。
示例代码如下。
<tcode> 我喜欢写代码 & lt;/tcode>
第二种方式是将特殊字符放到 CDATA 区,CDATA 内部的所有东西都会被 XML 解析器忽略,XML 解析器会将其当作文本原封不动地输出。当 XML 文件中需要编写一些不希望 XML 解析器进行解析的内容,例如,程序代码、SQL 语句或其他,就可以写在 CDATA 区中。
CDATA 区的定义格式如下所示。
<![CDATA [文本数据]]>
示例代码如下。
4.3 XML 约束¶
由于用户可以自定义 XML 标签,在开发过程中,每个人都可以根据需求来定义 XML 标签,这样就导致项目中的 XML 难以维护。因此,需要使用一定的规范机制来约束 XML 文件中的标签书写。XML 约束,即编写一个文件来约束 XML 文件的书写规范。它是由第三方应用程序或框架提供的,开发人员不必自己编写,只需引入使用即可。同样为 XML 文件,如果引入不同的 XML 约束,其内容也将大不相同。XML 约束主要包括 DTD 和 Schema 两种。
DTD 约束可以直接定义在 XML 文件中,也可以单独写成 DTD 文件,然后在 XML 中引入,引入外部 DTD 文件的语法格式如下。
<!DOCTYPE 根结点 PUBLIC "DTD 名称" "DTD 文件的 URL">
或者
<!DOCTYPE 根结点 SYSTEM "DTD 文件的 URL">
其中,根结点指的是当前 XML 文件中的根标签。PUBLIC 表示当前引入的 DTD 是公共的 DTD。SYSTEM 表示引入系统中存在的文件。“DTD 文件的 URL” 表示 DTD 存放的位置。
不过对于外部 DTD 约束,一个 XML 文件中只能引入一个 DTD 文件,并且 DTD 约束无法对 XML 中属性,以及标签中的数据进行数据类型的限定。Schema 约束对此进行了完善,它本身就是使用 XML 文件书写的,对 XML 的标签及属性,还有属性的数据类型、标签中子标签的顺序等具有严格的限定。如何编写约束文件,开发人员无须过多了解,只要掌握如何引入即可。
下面我们以 web.xml 的约束声明为例,进行简单说明。
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
其中,xmlns 用来指明根标签来自哪个命名空间。“xmlns:xsi” 表示引入 W3C 的标准命名空间。“xsi:schemaLocation” 用来指明引入的命名空间与哪个 “.xsd” 文件对应,包含两个取值,第一个值为命名空间,第二个值为 “.xsd” 文件的路径。
4.4 XML 解析¶
XML 解析指通过解析器读取 XML 文件,将数据解析成不同的格式。对 XML 的一切操作都是由解析开始的,因此解析非常重要。
4.4.1 解析方式简介¶
解析 XML 文件,主要有两种不同底层形式,一种是基于树形结构的 DOM 解析,另一种是基于事件流的 SAX 解析。DOM 是 W3C 组织推荐的处理 XML 的一种方式。SAX 不是官方标准,但它是 XML 社区实际上的标准,几乎所有的 XML 解析器都支持它。
- DOM(Document Object Model):翻译为文档对象模型,是基于树形结构的 XML 解析,也是 Java 自带的 XML 解析方式。它要求解析器把整个 XML 文件装载到内存,并解析成一个 Document 对象。解析之后,元素与元素之间仍保留结构关系,方便对其进行增、删、改、查操作。不足之处在于,如果 XML 文件过大,可能会出现内存溢出问题。
- SAX(Simple API for XML):基于事件流的 XML 文件解析。它是一种速度更快,更有效的方式,对 XML 文件逐行扫描,一边扫描一边解析,每执行一行,都会触发对应的事件。相比 DOM 解析方式,它不会出现内存问题,而且可以处理大的文件,但 SAX 解析只能从上到下按顺序读取文件,不能回写。
DOM 与 SAX 的对比如表 4-2 所示。
表 4-2 DOM 与 SAX 的对比
| DOM | SAX | |
| 速度 | 需要一次性加载整个XML文件,然后将其转换为DOM树,速度较差 | 顺序解析XML文件,无须将整个XML都加载到内存中,速度快 |
| 重复访问 | 将XML转换为DOM树之后,在解析时,DOM树将常驻内存,可以重复访问 | 顺序解析XML文件,已解析过的数据,如果没有保存,将不能获得,除非重新解析 |
| 内存要求 | 内存占用较大 | 内存占用率低 |
| 增、删、改、查操作 | 可以对XML文件进行增、删、改、查操作 | 只能进行解析(查询操作) |
| 复杂度 | 完全面向对象的解析方式,容易使用 | 采用事件回调机制,通过事件的回调函数来解析XML文件,略复杂 |
在这两种解析方式的基础上,基于底层 API 的、进行更高级封装的解析器也应运而生,比如面向 Java 的 JDOM、DOM4J 和 PULL 等。XML 解析技术体系如图 4-2 所示,DOM 解析相对简单,效率较高,后台多采用此种方式解析,需要重点掌握。而 SAX 解析主要适用于移动平台,这里了解即可。
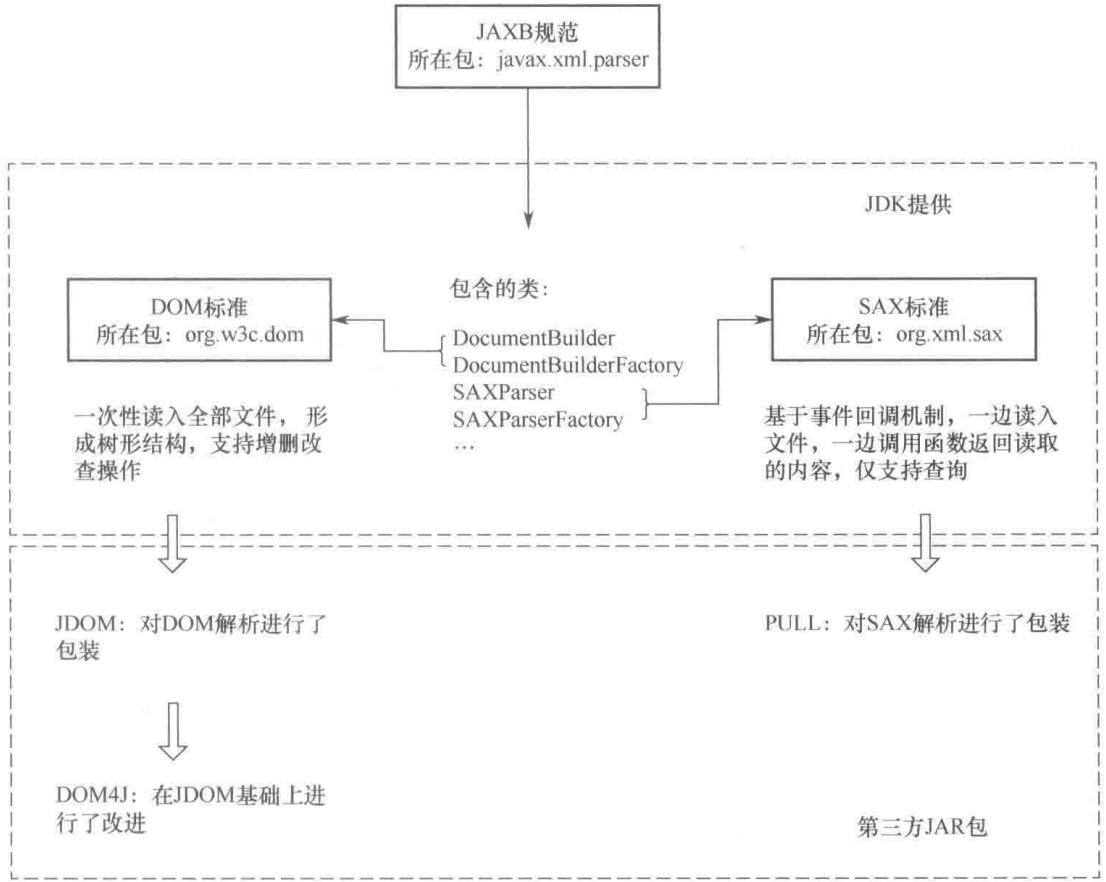
接下来,我们重点介绍一下 DOM4J 的常用 API,以及解析 XML 文件的具体步骤。
4.4.2 DOM4J 解析¶
DOM4J 是一个简单、灵活的开放源代码库,由早期开发 JDOM 的团队分离出来后独立开发。与 JDOM 不同的是,DOM4J 使用接口和抽象基类,虽然 DOM4J 的 API 相对要复杂一些,但它提供了比 JDOM 更好的灵活性。DOM4J 可以用于处理 XML、XPath 和 XSLT,它基于 Java 平台,使用 Java 的集合框架,全面集成了 DOM、SAX 和 JAXP。下面介绍 DOM4J 常用的 API。
- 创建 SAXReader 对象,读取 XML 文件。
- 解析 XML 获取 Document 对象,需要传入要解析的 XML 文件的字节输入流。
- 通过 Document 对象,获取 XML 文件中的根标签。
- 获取标签的子标签,包括获取所有子标签及根据指定标签名获取。
// 获取所有子标签
List<Element> sonElementList = rootElement.elements(); //获取指定标签名的子标签
List字段elementList = rootElement.elements("标签名");
- 获取标签的名字。
- 获取子标签体内的文本内容。
- 获取标签的某个属性的值。
了解了 DOM4J 的常用 API,接下来我们就可以应用它来解析文件了。使用 DOM4J 解析 XML 文件,具体步骤如下。
下面演示使用 DOM4J 对 teachers.xml 文件进行解析。teachers.xml 文件示例代码如下。
<?xml version="1.0" encoding="UTF-8"?>
<teachers>
<teacher id="1">
<tname>王老师</tname>
<tage>35</tage>
</teacher>
<teacher id="2">
<tname>张老师</tname>
<tage>50</tage>
</teacher>
</teachers>
使用 DOM4J 解析并遍历该文件,示例代码如下。
//1、创建解析器对象
SAXReader reader = new SAXReader( );
//2、使用解析器将 XML 文件转换为内存中的 document 对象
//注意:teachers.xml 位置是相对在项目根路径下查找 XML 文件
Document document = reader.read("teachers.xml");
//3、通过 Document 对象可以获取 XML 文件的根标签
Element rootElement = document.getRootElement( );
//4、根据根标签获取所有根标签的子标签集合
List fell> elements = rootElement.elements( );
//5、遍历集合中的标签,并将所有的数据解析出来
for (Element element : elements) {
//每次遍历就代表一个 teacher 信息
System.out.println("正在遍历的标签名:" + element.getName( ));
System.out.println("正在遍历标签的 id 属性值:" + element.attributeValue("id"));
//获取 teacher 的子标签的内容
String tname = element PromotionText("tname");
System.out.println("tname: "+tname);
String age = element.elementText("tage");
System.out.println("tage:" + age);
System.out.println("--------");
另外,DOM4J 还能够对 XML 文件进行增、删、改操作。例如,使用 DOM4J 对 teacher.xml 文件进行修改,演示添加新结点、修改 XML 文件的格式,该内容了解即可,示例代码如下。
SAXReader reader = new SAXReader();
Document document = reader.read("teachers.xml");
Element rootElement = document.getRootElement();
//添加一个新的 teacher 结点
Element newEle = rootElement.addElement("teacher");
//创建一个良好的 xml 格式
OutputFormat format = OutputFormat.createPrettyPrint();
//写入文件
XMLWriter xmlWriter = new XMLWriter(new FileWriter("teachers.xml"), format);
xmlWriter.write(document);
xmlWriter.close();
在 teachers.xml 文件中,使用 DOM4J 创建 XML 文件,并添加 teacher 结点,示例代码如下。
//1.创建XML文件
Document document = DocumentHelper.createDocument();
//2.添加根元素
Element root = document.addElement("teachers");
//3.添加元素结点
Element tcEle = root.addElement("teacher");
Element tcEle2 = root.addElement("teacher");
4.5 本章小结¶
本章介绍了 XML 的基础语法,明白一个标准的 XML 文件应该由文件声明、元素、属性、注释、特殊字符几部分组成。了解到 XML 文件的应用十分广泛,可以进行数据存储、数据交换,尤其经常用来作为各种应用程序的配置文件使用,这也是需要重点掌握的部分。还介绍了 XML 约束,学习到编写 XML 文件不仅需要遵循 XML 基本语法,还要符合第三方应用程序或框架给定的 XML 约束。最后介绍了 XML 解析,并重点讲解了使用 DOM4J 解析 XML 文件的全过程。通过本章学习,相信初学者将会对 XML 产生更深一步的理解,也为后续的学习奠定坚实的基础。